


Is Science Trustworthy - The Theory of Measurement
The problem of operationalizing measurement

One of the most important aspects of science, a requirement without which it cannot be performed, is the collection of data through measurement. It is through the collection of this evidence that we may falsify existing scientific theories and propose new ones. When expressed properly, this evidence should be in the form of testimony that when performing a series of objective operations, certain results were observed. There are however many different ways of collecting data, from simple naturalistic observations to complex controlled experiments. In practice data is collected in a manner described in the experimental design, the data is analyzed, usually using quantitative or statistical techniques, and then the results are interpreted and reported. This essay discusses operationalization and the theory of measurement.
Data collection should be structured operationally, as discussed in part 1. The series of actions and measurements taken during a scientific investigation should be algorithmic, without requiring the subjective judgment of the individual researcher.1 This ensures that the experimental methodology is replicable by other researchers, and removes the researcher’s individual bias and interpretation from the raw data. An operational description should also strip all theoretical loading from the experimental methodology. For instance, a virologist might report the concentration of viruses in a solution. This might sound like an objective fact, however it is really a theoretical interpretation applied to some objective observations. An operational account might be that a given solution, after ten-thousandfold dilution, caused two plaques to form on a confluent monolayer cell culture.[1] This is then interpreted under virological theory as being the result of viral infection of the cells, and used to calculate viral concentration. Stripped of theoretical loading, the operational statement could, if necessary, be reinterpreted under a new theory, if the current theory applied to the results is later falsified, or a non-viral entity was found to be causing the plaques.
Operationalism also ensures that scientific theories make contact with reality somewhere. If we have no operationalizations of consciousness, then we must concede that it is not currently possible to investigate consciousness scientifically. This also means that operationalizations must be practicable. If the only operationalization available for measuring the distance from Earth to Alpha Centauri is to use a meterstick, then it is not in fact possible to determine the distance to Alpha Centauri scientifically, since it is not feasible to carry out the experiment. Our theory of physics may say that everything has a length, and this may have resisted falsification, but we would not be able to have a scientific discussion about the specific distance from Earth to Alpha Centauri.
A specific example will serve to demonstrate the importance of operationalism. Consider the length of the coastline of Great Britain. This is a perimeter, expressed as a length, which is usually considered a pretty objective measurement. Yet, the CIA Factbook gives the length as 12,429 km and the World Resources Institute gives the length as 19,717 km. The reason is that the operationalization is different for each measurement. Given the jagged, fractal-like structure of a coastline, the length of the ruler used will determine the amount of detail that can be observed and incorporated into the final length. A shorter ruler will produce a longer overall measurement. This means that the length figure is actually uninterpretable without understanding how exactly the measurement was made. It would certainly be inappropriate to compare the perimeter of Great Britain measured with a ruler of one length to the perimeter of Australia measured with a ruler of a different length. The length of the coastline of Great Britain is then a theoretical construct that only makes contact with reality where it can be operationalized by a particular way of measuring it.

Length in general (that is, straight-line Euclidean distance2) and the ways in which it is measured serves as a good case study in the philosophy of measurement. The most obvious operationalization of length, measurement with a ruler or other object of standard length, is also one of the most ancient forms of measurement used by humans. It is as simple and theory-free as it is possible for a measurement to be, and does not require any additional steps or auxiliary results. Measurement with a ruler can then be used as a gold standard to test and calibrate other methods of measuring length. Triangulation and trilateration are two other methods, but require knowledge of geometry and some intermediate results: at least one distance and one angle measurement for triangulation, and at least three distance measurements for trilateration. Radar is another technique that can be used to measure distances, and involves making a single time measurement of the duration between emission and detection of a radio wave signal. Unlike using a ruler, accurate radar measurements require advanced knowledge of optics and electromagnetism, and achieving high precision requires specialized equipment as well as techniques to account for noise and interference.
At astronomical distances, rulers can no longer be used, and so various measurement techniques of increasing complexity are employed to measure longer distances in terms of shorter ones. This is called the Cosmic Distance Ladder. Radar forms the base, being used to establish distances within the solar system. The next rung on the ladder comes from nearby stars, the distances to which are calculated via triangulation based on the parallax observed at opposite points in Earth's orbit. This measurement requires a theory of how the Earth moves in the solar system, and depends on the accuracy of measurements of the Astronomical Unit, made by radar. Further rungs quickly add complexity: measurements of more distant stars in the Milky Way are based on fitting an empirical model defining the relationship between a star's luminosity and its emission spectrum, called main-sequence fitting. It relies on advanced photometric techniques that need to correct for luminosity attenuation over distance, star variability, interstellar dust clouds, and many other issues. The next rung, measuring distances to nearby galaxies, is also based on an empirical relationship, this time between the period and luminosity of Cepheid-class variable stars, and again requires much theoretical, empirical, and technical scaffolding. Skipping to the end, the final rung calculates distance by measuring the redshifts of distant objects, which is interpreted in light of the universal expansion posited by Big Bang cosmology. At this scale the interpretations of the data are still the subject of active research in mainstream physics, and discrepancies of up to 10% in the crucial Hubble constant remain unresolved.
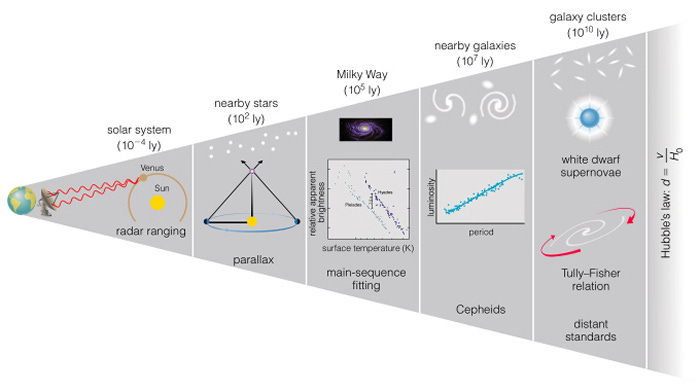
The cosmic distance ladder demonstrates the extraordinary diversity of operationalizations for calculating Euclidean distance - one of the most intuitive measurable quantities in science. Therefore, despite purporting to measure the same basic quantity, a comparison of length measures obtained through very different means cannot necessarily be considered an apples to apples comparison. Once again, if you do not know the way a measurement was obtained, you do not truly understand what it means. The accuracy of distance measurements on astronomical scales is inextricably dependent on thousands of previous theoretical and empirical results in ways that cannot be captured by a simple margin of error. Interpretation of results at galactic scales is incredibly theory dependent, and a shift in our understanding of Cepheid stars could force the reinterpretation of millions of results. A shift in our understanding of cosmology could derail the very idea that there is a relationship between redshift and distance. The situation is similar on very small scales as well, and in fact many results pertaining to molecular geometries (e.g. bond lengths, angles, etc.) are not even measured, they calculated with purely theoretical ab initio methods in computational chemistry (which can itself take many forms). If we take Bridgman's view, as discussed in the part 1, that "we mean by any concept nothing more than a set of operations" then we would have to consider each of these ways of measuring length as being fundamentally different concepts. To resolve Bridgman's contention, we can apply nomological networks as a means of unifying disparate measures.
Nomological networks as a concept emerged from psychology at a time when the operationist school of behaviourism was ascendant. They were presented most influentially in a 1955 paper by Cronbach and Meehl:
1. Scientifically speaking, to "make clear what something is" means to set forth the laws in which it occurs. We shall refer to the interlocking system of laws which constitute a theory as a nomological network.
2. The laws in a nomological network may relate (a) observable properties or quantities to each other; or (b) theoretical constructs to observables; or (c) different theoretical constructs to one another. These "laws" may be statistical or deterministic.[2]
The various theories about stellar parallax, Cepheid stars, and red shift that underlie the cosmic distance ladder would then be considered the laws of the nomological network that links astronomical observations to calculated distances. In the nomenclature of nomological networks, length is a criterion measure, because there is a clear operational definition that we can use to measure a length directly. Having such a measure as a criterion, we can then use it to validate the predictive or concurrent validity of other candidate measures of the same quantity. When the measures agree, we consider the new measure as possessing criterion validity; when they do not agree, the new measure is considered as lacking validity (the original measure, being the criterion, is not in question). Concurrent validity is established when both measures are made at essentially the same time, while predictive validity is established when the criterion measurement is made later. The more complete the nomological network, and the more agreement there is between different measurement operationalizations, the more confident we can be that the different operationalizations are in fact measuring the same quantity. But the more difficult case, and the one that nomological networks were invented to solve, is when there is no criterion measure.
Many of the constructs studied in psychology do not permit direct measurement. Consider anxiety. Psychology applies various operationalizations to measure anxiety: self-report scales, structured interviews, physiological measures like heart rate and cortisol levels, behavioural observations of avoidant behaviour, or performance on psychological tasks in the presence of anxiety-provoking stimuli. While all of these correlate and are related to anxiety, it is not possible to pick any of them as the criterion by which anxiety should be measured; anxiety is a latent construct which expresses itself in each of the measurement methods, but isn't synonymous with any of them. Therefore, the specific observables must be assembled into a nomological network that describes the construct: anxiety is synonymous with the network itself. This also means that if the network changes - say to accommodate new data - that is, in effect, redefining the construct.3 Therefore "[w]e will be able to say "what anxiety is" when we know all of the laws involving it; meanwhile, since we are in the process of discovering these laws, we do not yet know precisely what anxiety is."[2]
While a nomological network can provide a definition for an unobservable construct, it does not perforce mean that it is a good or useful one. In order to demonstrate that it is scientifically relevant, the content and construct validity of the network must be established. Construct validity has two components: convergent and divergent validity. A construct has convergent validity if different ways of measuring it (observables in the nomological network) actually correlate. A construct has divergent validity if the observables it entails do not correlate with things that should be unrelated according the to network. Divergent validity is very important because it is often the case that a new psychological construct is found to simply be a relabeling of a previously known construct.4 The last piece, content validity, is about ensuring that a network covers all of the different facets of the construct it purports to represent. The network representing anxiety could hardly be complete if it did not include such behavioural observables as stress-induced withdrawal or volatility.
This discussion of construct validity is apposite to the question of the reliability of scientific results because it is too often the case that constructs are applied in scientific investigation using different operationalizations when there is no consistent theoretical or nomological foundation for linking the different measurements. Socioeconomic status (SES) is a common offender: a 2023 review found that across 152 studies from the past twenty years there were 147 different operationalizations of SES, and that moreover almost 80% of studies did not offer any theoretical definition for the construct (and where definitions were offered they often differed).[3] This is especially relevant because SES is a formative model, not a reflective model like anxiety.[4] That is, with anxiety, there is an underlying thing that causes the different observables. With SES, there is no underlying thing that causes income and educational attainment5 - it is simply a label that is applied to a set of observables. The causation goes the other way, and so using a different set of observables results in a fundamentally different construct. This leads to conflicting claims in the literature that high-SES individuals were both more likely to vote Republican and to report less stress, and simultaneously less likely to do the same. Researchers treat different operationalizations of SES as interchangeable even though they are not, and consequently cite other papers as supporting their hypotheses when they use entirely different measures. Such shoddy methodology vitiates large portions of the psychological and sociological literature, which becomes completely unreliable when taken at face value.
References:
Dulbecco, R., & Vogt, M. (1953). Some problems of animal virology as studied by the plaque technique. Cold Spring Harbor Symposia on Quantitative Biology, 18, 273–279. https://doi.org/10.1101/sqb.1953.018.01.039
Cronbach, L. J., & Meehl, P. E. (1955). Construct validity in psychological tests. Psychological Bulletin, 52(4), 281–302. https://doi.org/10.1037/h0040957
Antonoplis, S. (2023). Studying Socioeconomic Status: Conceptual Problems and an Alternative Path Forward. Perspectives on Psychological Science: A Journal of the Association for Psychological Science, 18(2), 275–292. https://doi.org/10.1177/17456916221093615
Coltman, T., Devinney, T. M., Midgley, D. F., & Venaik, S. (2008). Formative versus reflective measurement models: Two applications of formative measurement. Journal of Business Research, 61(12), 1250–1262. https://doi.org/10.1016/j.jbusres.2008.01.013
Amabile, T. M. (1982). Social psychology of creativity: A consensual assessment technique. Journal of Personality and Social Psychology, 43(5), 997–1013. https://doi.org/10.1037/0022-3514.43.5.997
Ponnock, A., Muenks, K., Morell, M., Seung Yang, J., Gladstone, J. R., & Wigfield, A. (2020). Grit and conscientiousness: Another jangle fallacy. Journal of Research in Personality, 89, 104021. https://doi.org/10.1016/j.jrp.2020.104021
Kirkegaard, E. O. W. (2022, April 15). National “learning-adjusted years of schooling.”

This opens the question of how certain measures in psychology that involve subjective judgement, like personality questionnaires or expert rating, could be considered scientific. The reason is because they do not require subjective judgement on the part of the researcher. When an expert rater reviews something, as in Amabile 1982, they produce a quantitative, though subjective, rating.[5] The researcher can then treat the results as originating from a black box measurement device with a relatively high amount of measurement error, which is entirely scientific. The same logic can be applied to the use of deep learning models performing scientific measurements. The specifics of the subjective measurement need to be considered when interpreting the data, but the measurement itself can be considered scientific, despite involving subjectivity.
There are of course other kinds of length, like the length of a curve, or the distance between two points in spherical or hyperbolic geometry, but these are complexifications that require different theoretical and mathematical machinery and will not be addressed here.
Note that this logic does not apply to concepts which permit criterion measures, since there the nomological network is used to justify different operationalizations of the same quantity, not to define the quantity in itself.
For instance the popular psychological construct Grit is the same as Conscientiousness in the Big 5.[6] This also ends up happening when a particular construct is politically taboo, but keeps showing up in analyses. For instance, economists rediscovering national IQ but calling it "learning-adjusted years of schooling".[7]
Arguably that thing is genetics, although that is outside the scope of what socioeconomic status represents as a construct.